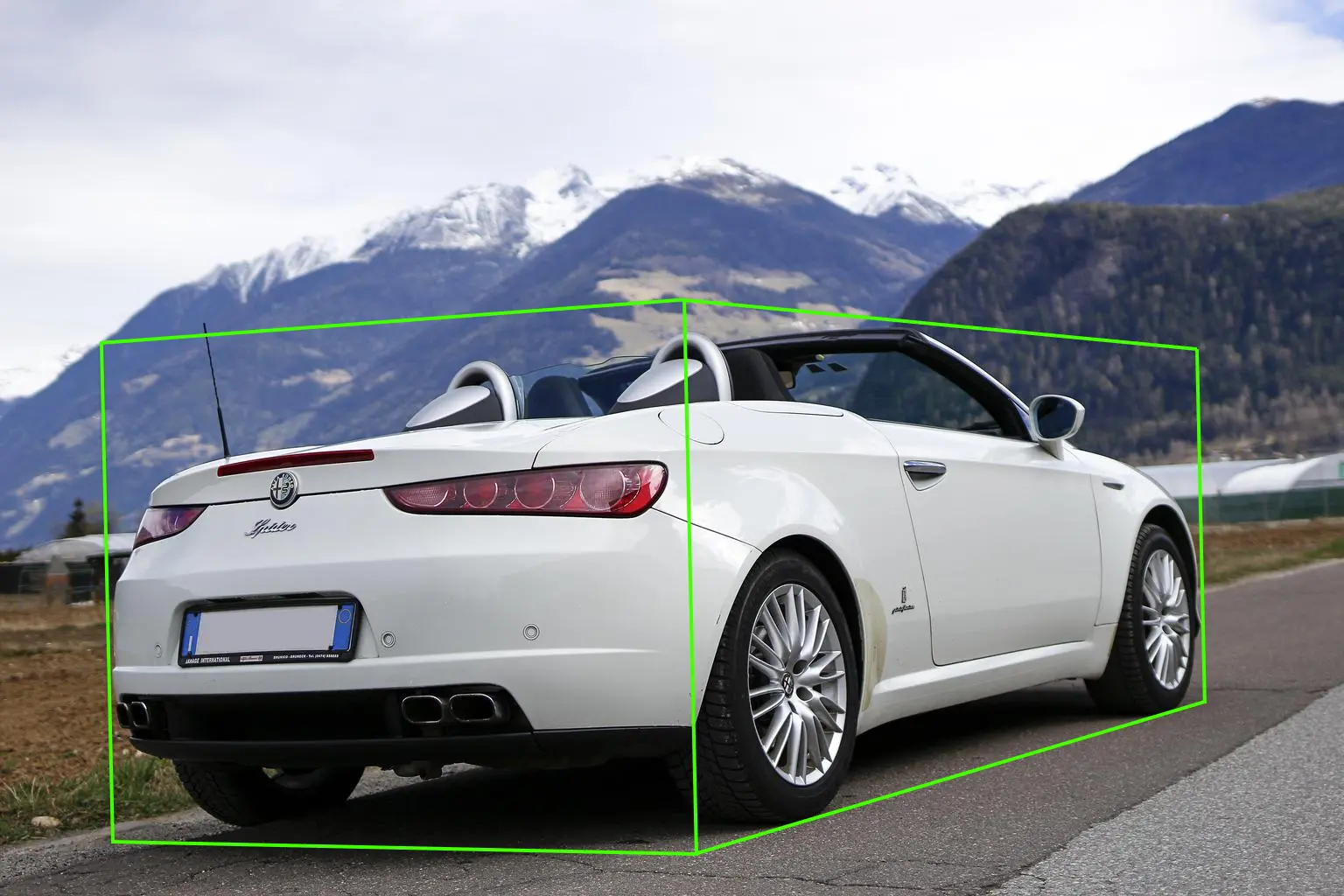
Image Annotation Techniques
Image annotation techniques involve adding metadata or labels to images to enhance their searchability, understandability, and analysis. These techniques include object detection, semantic segmentation, image classification, and captioning. Object detection identifies and localizes objects within an image, while semantic segmentation assigns pixel-level labels to various objects. Image classification categorizes images into pre-defined categories, and captioning generates natural language descriptions of an image. These techniques are widely used in fields such as computer vision, machine learning, and data analysis to improve image retrieval, recognition, and understanding.